
DeepSeek-MoE is a large language model (LLM) with 16.4B parameters. It is based on the Mixture-of-Experts (MoE) architecture, which allows it to achieve high performance with relatively low computational cost. Inshort, It’s a model that leverages the Mixture of Experts (MoE) framework, which allows it to perform complex tasks efficiently. Curious about how it works? Well, the Mixture of Experts framework assigns tasks to specialized expert networks, each one focuses on a specific area.To give the most accurate output A gating mechanism decides which expert is best suited for a specific task. To better understand the concept we will go through this page and simplify the basic concept.
What is DeepSeek-MoE?
DeepSeek is a large language model built on the Mixture of Experts framework. If we compare it then It is not like other traditional models that activate all their parameters for every task, MoE selectively activates only the necessary experts for a given input. This makes it highly efficient in terms of computation and specialization. Essentially, DeepSeek optimizes performance while keeping resource consumption in check, a balance that’s difficult to achieve with conventional architectures.
The backend working based on this division makes work faster, even smarter and capable of handling a number of inputs in a more efficient way.
Basic Concept Of Mixture Of Expert Framework
To put it simply, Mixture of Experts is like having a team of specialists instead of a jack-of-all-trades. Instead of relying on a single model to process all kinds of information, MoE breaks tasks into smaller parts and assigns them to specialized sub-models called experts. A gating network acts as a decision-maker, directing inputs to the most relevant experts. This results in a more efficient and precise output.
Think of it like visiting a hospital. Instead of one doctor handling everything, you have cardiologists, neurologists, and orthopedic specialists who focus on their respective fields. This targeted approach ensures better diagnosis and treatment, just as MoE enhances AI performance. And the best part? DeepSeek is free to use, so you won’t be charged for any additional feature.
DeepSeek–MoE Architecture
DeepSeek AI selectively activates only a few experts, significantly reducing computational overhead. The model also incorporates techniques to balance workload distribution across experts, preventing any single expert from being overburdened. This balance ensures that the system remains stable and doesn’t suffer from inefficiencies due to uneven task allocation.
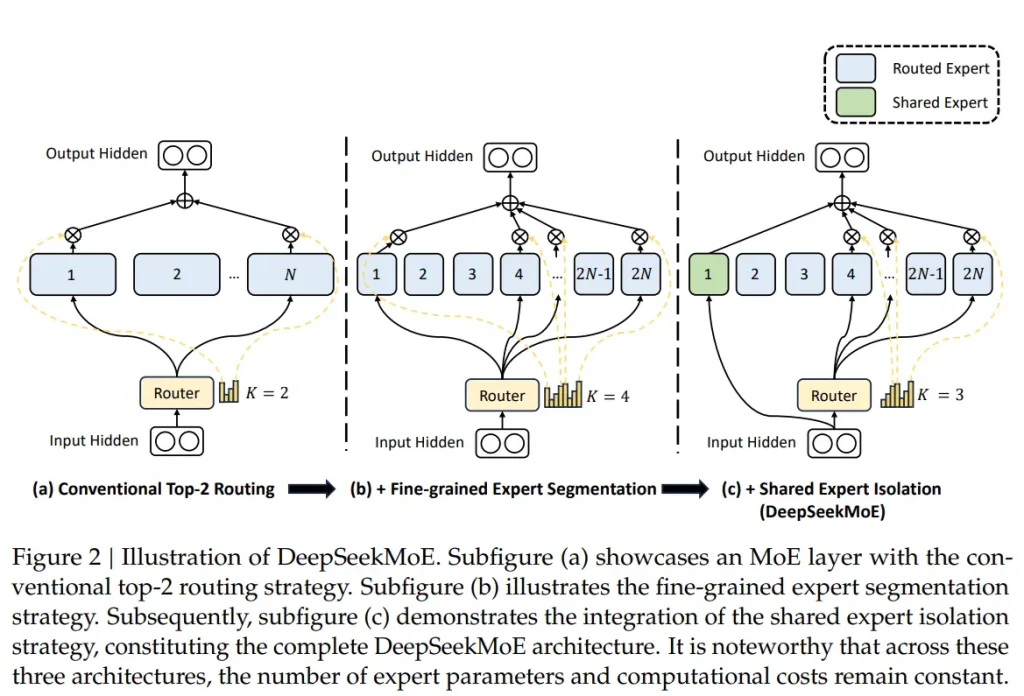
Applications of DeepSeek-MoE
The applications of DeepSeek-MoE span multiple domains. It excels in natural language processing, offering better text generation, summarization, and translation capabilities. In finance, it aids in predictive analytics, risk assessment, and fraud detection. Healthcare also benefits from this technology, as it helps in diagnosing diseases by analyzing vast medical datasets.
DeepSeek Mixture-of-expert architecture applies the MoE framework in a way that maximizes both scalability and accuracy. By leveraging specialized experts, it can perform a diverse range of tasks with remarkable precision. Whether it’s language modeling, data analysis, or predictive analytics, DeepSeek intelligently assigns tasks to the most capable expert networks.
The beauty of this system is its adaptability. It can continuously learn and adjust, so that as new data emerges, the right experts are engaged. This means that DeepSeek isn’t just efficient, it’s also highly dynamic and responsive to different types of input provided to it.
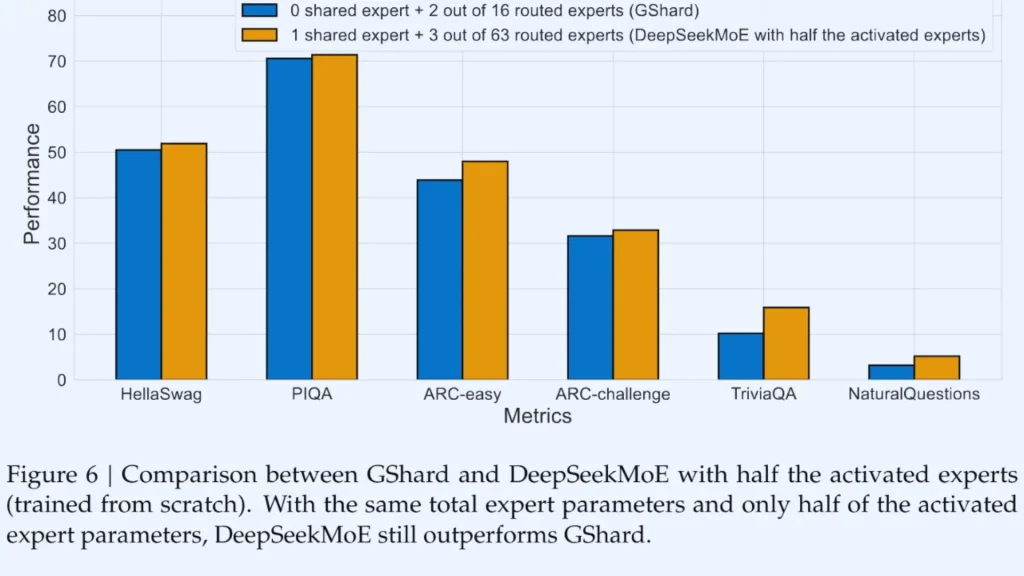
Benefits of DeepSeek-MoE Architecture
Enhanced Parameter Efficiency
One of the standout benefits of this architecture is its ability to utilize parameters efficiently. Unlike traditional models that activate all parameters, MoE selectively engages only the necessary ones. This means that computational resources are used more effectively, leading to faster processing speeds and reduced energy consumption.
Mitigation of Redundancy
Because experts are specialized, there is far less redundancy in DeepSeek compared to conventional AI models. Each expert focuses on a specific area, eliminating unnecessary computations and making the system more streamlined. This results in faster execution and more accurate outcomes.
Higher Expert Specialization
Specialization is what makes DeepSeek so powerful. Each expert network is trained on specific types of data, ensuring that they become highly proficient in their domain. This focused learning approach leads to better performance, as opposed to models that try to do everything at once without true mastery in any area.
Improved Load Balancing
With a well-structured gating network, DeepSeek ensures that computational loads are distributed evenly across experts. This prevents bottlenecks and optimizes performance, making the model both scalable and reliable.
Flexibility in Knowledge Acquisition
DeepSeek isn’t static, it evolves. The model can integrate new knowledge seamlessly, allowing it to adapt to changing information landscapes. Whether it’s learning new languages, adapting to new research findings, or improving predictive capabilities, DeepSeek MoE remains flexible and future-proof.
The Future of DeepSeek-MoE
Looking ahead, DeepSeek-MoE has the potential to redefine AI applications. As technology advances, we can expect even more efficient architectures, further reducing computational costs while improving accuracy. AI models like DeepSeek will likely become more integrated into everyday applications, making advanced AI accessible to businesses and individuals alike.
The challenge will be refining MoE frameworks to further minimize latency and ensure fair expert utilization. But with continuous research and development, DeepSeek is poised to remain at the forefront of AI innovation.
You can also explore the key features of DeepSeek and if you are curious to know is DeepSeek safe.